Abstract
Support Vector Machines (SVM) is the crown jewel of optimization theory and has become a very popular tool for classification. SVM is easily invoked by any machine-learning library. It can calculate a curvilinear decision boundary by lifting the inseparable classes into a higher N-Dimensional space where an [N-1]-Dimensional hyperplace can separate the data with remarkable accuracy, precision, and recall; however, like many advanced algorithms in optimization theory, notwithstanding the algo’s ability to classify a class, no insight into the problem set’s data-generating function is obtained by applying the SVM algorithm. Of course, if the DGF’s causal factors are unknown or unknowable, and a classification must be made, SVM is unsurpassed, but in industrial and applied mathematics, there is a strong interest in indentifying causal factors that affect the revenue, costs, margins, and profits of the business firm so that predictive and prescriptive algorithmic tools can be deployed to optimize operations. In this problem space, multivariate linear regression with causal factors is unsurpassed. This article shows how a curvilinear decision boundary that is the purview of SVM can be transformed to a linear decision boundary with elementary analytical techniques, where logistic regression can make a perfect classification. We celebrate Vapnik’s SVM, but we argue that its problem domain is far downstream from the typical industrial problem set, and indeed that elementary analytics can take you far when coupled with causal factors and traditional regression algorithms for scoring and classification.
Discussion
William Faulkner and Ernest Hemingway had an erudite, public disagreement. Faulkner resented Hemingway’s terse, concise, compact prose, which no doubt was informed if not preordained by Hemingway’s long stint as a newspaper correspondent with the Kansas City Star and Toronto Star Weekly. Western Union charged by the word, so concision was key. Furthermore, Hemingway was in esteemed company of journalism alumni – Mark Twain, Stephen Crane, Theodore Dreiser, and Sinclair Lewis, among others, once wrote by the column inch. Faulkner was unimpressed by the association. He said of Hemingway that Hemingway had no courage, that he had “never been known to use a word that might send the reader to the dictionary.”
Hemingway was having none of it. “Poor Faulkner. Does he really think big emotions come from big words? He thinks I don’t know the ten-dollar words. I know them all right. But there are older and simpler and better words, and those are the ones I use.”
Simple tools, in the hands of the master, take you far.
I reflect on this exchange often in my professional practice of industrial and applied mathematics. There are many powerful software packages available to machine-learning technicians, and the algorithms are the result of decades of advancements in optimization theory. The algorithms can mine the data to recognize even the most subtle and obscure patterns, and cluster, associate, correlate, score, and classify even the most seemingly intractable datasets. For many of the algorithms, very little understanding of the underlying causal factors that produce the data is required, in which case, the impressive algorithmic results give little business or industrial insight into the data source and character. Root cause can be as elusive after the successful application of the algorithm as before. Nevertheless, buoyed by black-box prestidigitation, aspiring data scientists increasingly rely on such statistical packages at the expense of root-cause business analysis.
(At least) two things are missing in this approach.
First, the role of the scientist is understanding. In the context of data-science discovery, understanding emerges from investigating, hypothesizing, testing, identifying, and validating the mathematical, physical, statistical, and geometrical properties that characterize the problem set’s data-generating function. It is from this model that reproducible, tunable, predictive, and prescriptive analysis is possible.
This vocation is not for the faint at heart. The analyst must lean into the problem and challenge the mathematics, perhaps with unrequited enthusiasm; despite the analyst’s best efforts, the problem may not budge. We kiss many proverbial frogs. We punt. A lot. Progress sometimes becomes regress. Alternating periods of disappointment, confusion, elucidation, sleeplessness, and fleeting excitement are constant companions until the problem is cornered in a cul-de-sac of analysis and the solution stands tall and alone. It is the answer because it could be no other. And no sooner than that solution is deployed do we start again.
It is this dogged, blue-collar, full-contact, actively-engaged, erudite analysis that is the corpus of scientific discovery. It is the nimble, dexterous, virtuosi application of maths, Multiphysics, statistics, hypothesis testing, and simulation all to isolate and explain a conjectured effect that may have no discernable cause using an experiment that may not work, and subsequently prevailing after all of that. It is for this immutable reason that we scientists can immediately recognize one of our own; the craft is both wide and deep. Especially deep.
Secondly, despite the outrageous claims of software vendors and the preternatural aspirations of young data “scientists,” black-box software algorithms cannot replace this understanding, else dexterity with TurboTax would qualify one as a tax attorney or Quicken as a chartered accountant.
Armed with software that seemingly — but importantly, not actually — outpaces one’s numeracy, it is common sport for young aspiring data scientists to apply the most powerful machine-learning algorithms to even the most tractable analytic problem sets and, in the process, to forego mathematical and statistical analysis en route to classifying, scoring, clustering, and associating data. Sometimes the software is faithful to the Hippocratic Oath to first do no harm, then help, but sometimes not. It is a fool’s errand exactly because the goal of the craft is not to make the classifications and calculate the scores, but rather to discern the causal factors that comprise the data-generator of the data.
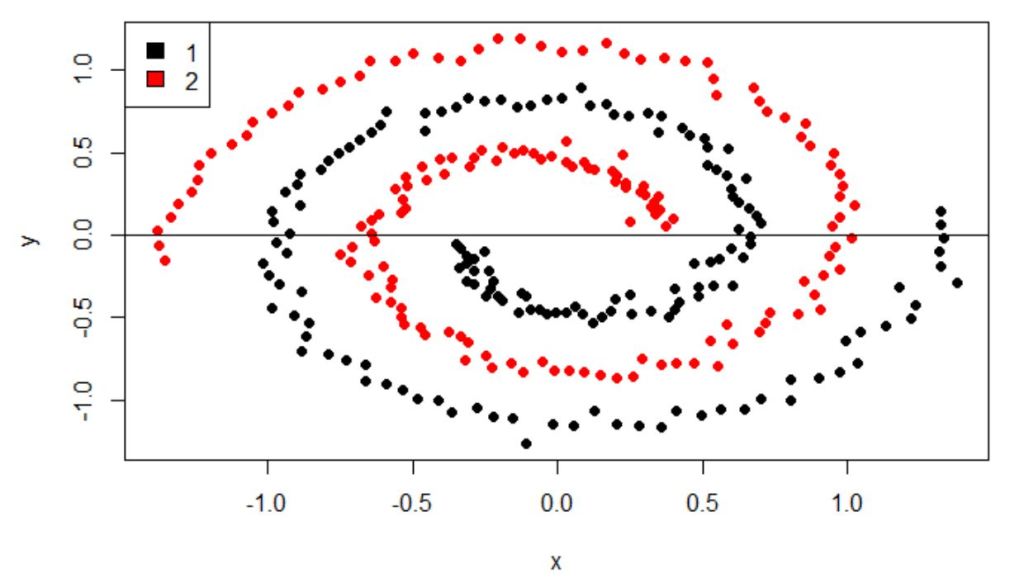
This small article uses an illustrative problem set in a seemingly non-linear decision boundary to benchmark one of optimization theory’s crown jewels, the Support Vector Machine, to highlight the power of this amazing algorithm to learn a seemingly intractable decision boundary.
We then improve on this result by applying analysis and invoking an old workhorse, the logistic-regression, to illustrate how domain knowledge and elementary mathematical tools can take us far. Vapnik and the 20th century’s optimization-theoretical gems are to be celebrated, but Archimedes, Pythagoras, Decartes, Newton, and Gauss are our guides for a good long while in this business.
Let’s get started.
DOWNLOAD THE PAPER BELOW TO CONTINUE READING…

One response to “Analytical Construction of a Linear Decision Boundary for Machine-Learning Classification by Regression”
[…] article extends a previous article on the analytical construction of a curvilinear classification decision boundary using Multivariate […]
LikeLike